
From a few train grid pairs, infer a general transformation rule…
Do LLMs have fluid intelligence?
Lessons from competing in ARC AGI 2

TNG Big Techday 26
2026-05-22
About us
and many thanks to everyone involved!
Debsankha Manik

Dynamical systems, graph theory; data science × discrete optimisation.
Loves teaching.
Bernhard Altaner

Thermodynamics and information processing in complex systems.
Has local GlaDOS in his smart home.
Supported by Nicolas Berg – co-host of the AGI Munich meetup.
Thank you to Somayeh Vojdani & Tariq Baig-Meininghaus for initial discussions and continued encouragement.
Thanks to lambda.ai for providing free credits that helped support this research.
ARC-AGI as a general intelligence benchmark
What constitutes general intelligence?
Raymond Catell, 1948, defined two aspects of general intelligence
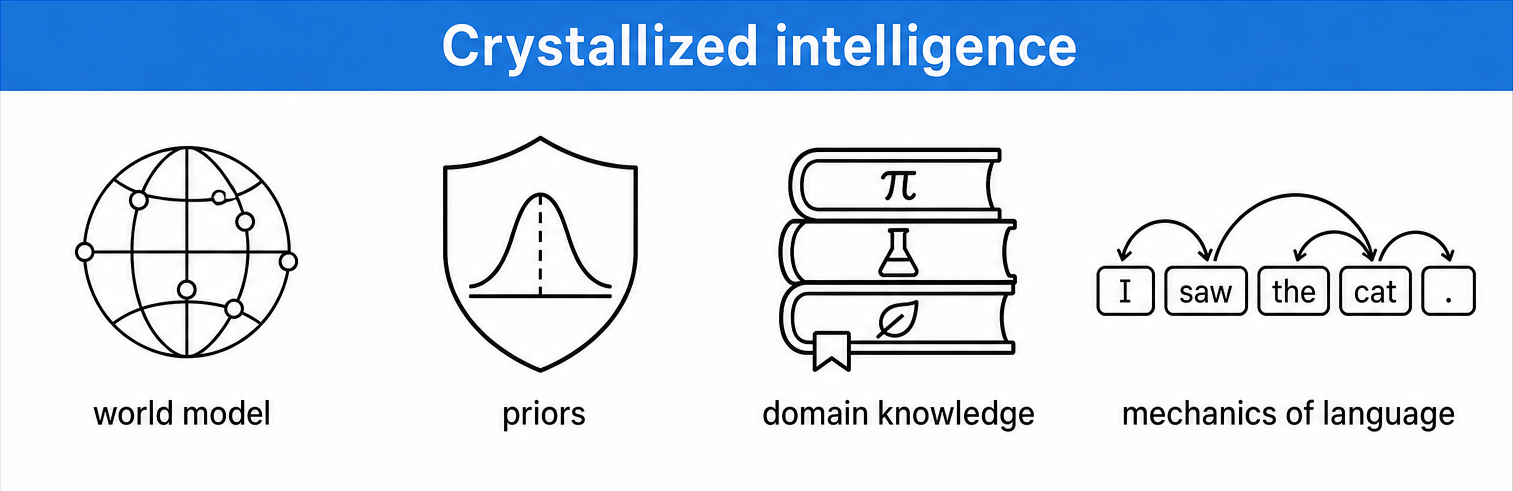
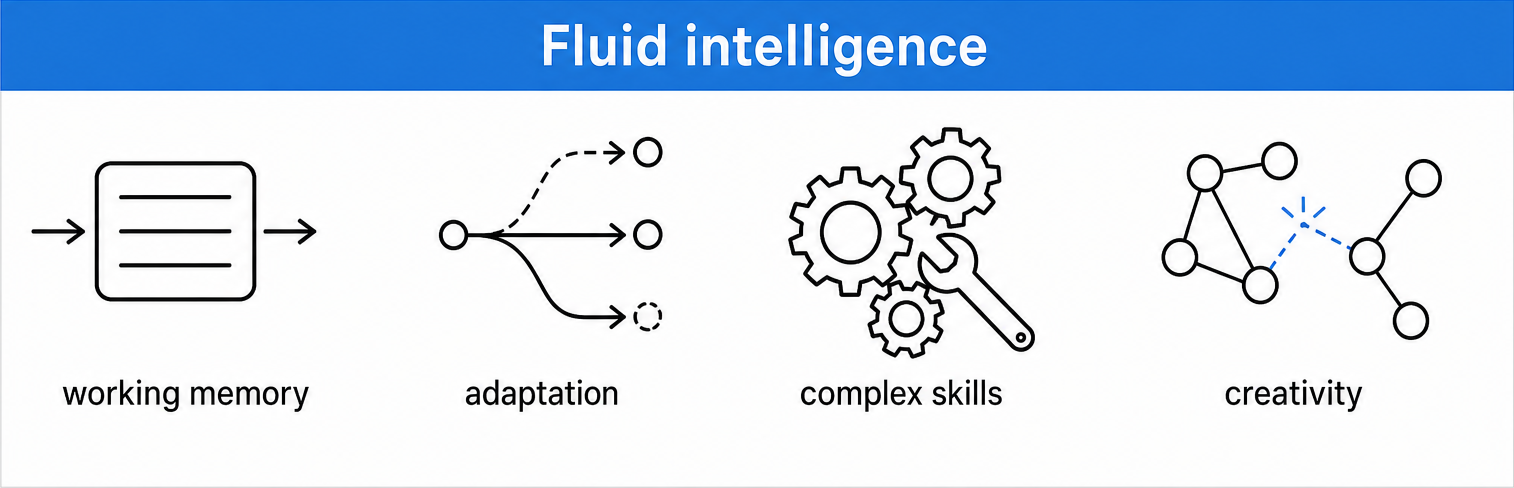
General intelligence combines knowledge with adaptation!
- ARC AGI designed to test skill acquisition efficiency1, a hallmark of fluid intelligence.
- Requires In-Context-Learning, i.e. adaption to new situations not encountered in training data.
- Essential problem: AI model weights are frozen during inference.
- So how could LLMs ever exhibit fluid intelligence?
State of the ARC in April 2025
On the shoulders of giants
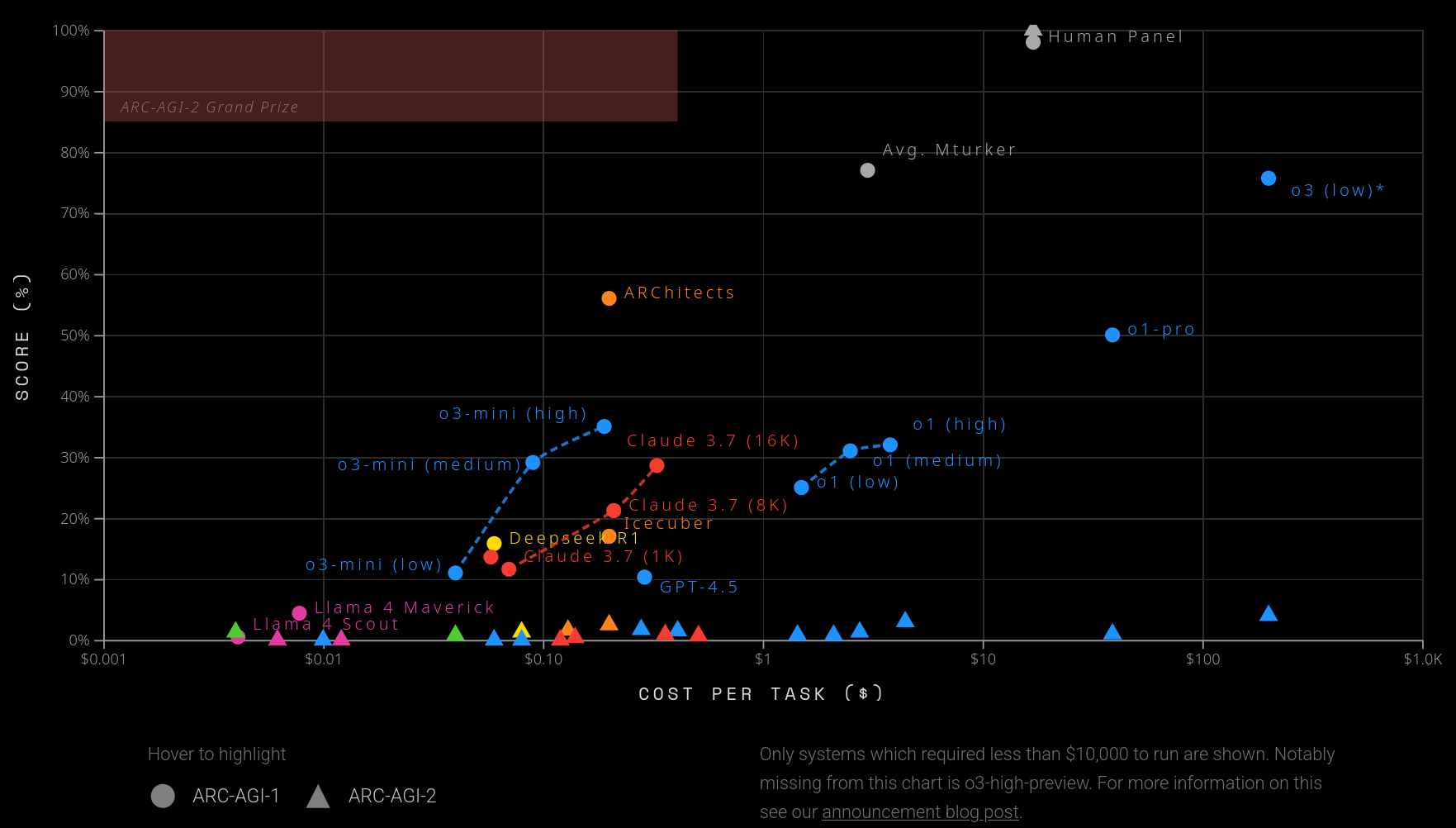
⏺ ARC-AGI 1: Not saturated; multiple paradigms used; reasoning models give good results, but expensive
▲ ARC-AGI 2: barely any scores beyond noise (~3%) level
Challenge accepted!
Curiosity-driven YOLO meets Dunning-Krueger
- Reasoning models seemed like an an interesting way to scale compute during test time
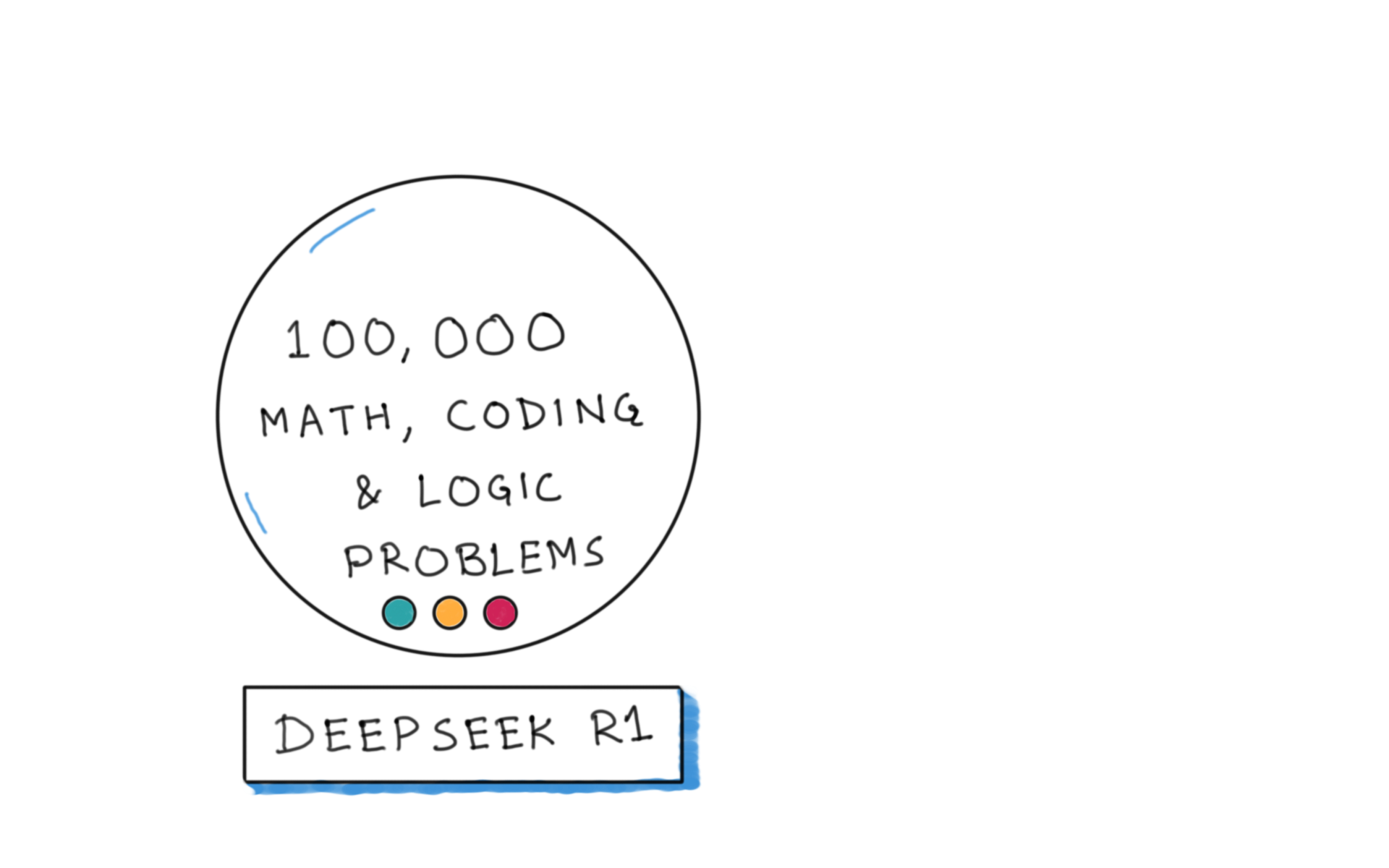
- Deepseek R1 and its distillates had just been released
- Straightforward plan:
- Step one: Generate synthetic data for this domain.
- Step two: Fine-tune a small open weights models and introduce reasoning like Deepseek R1 with reenforcement learning.
- Step three: Profit!
- How hard could it be?

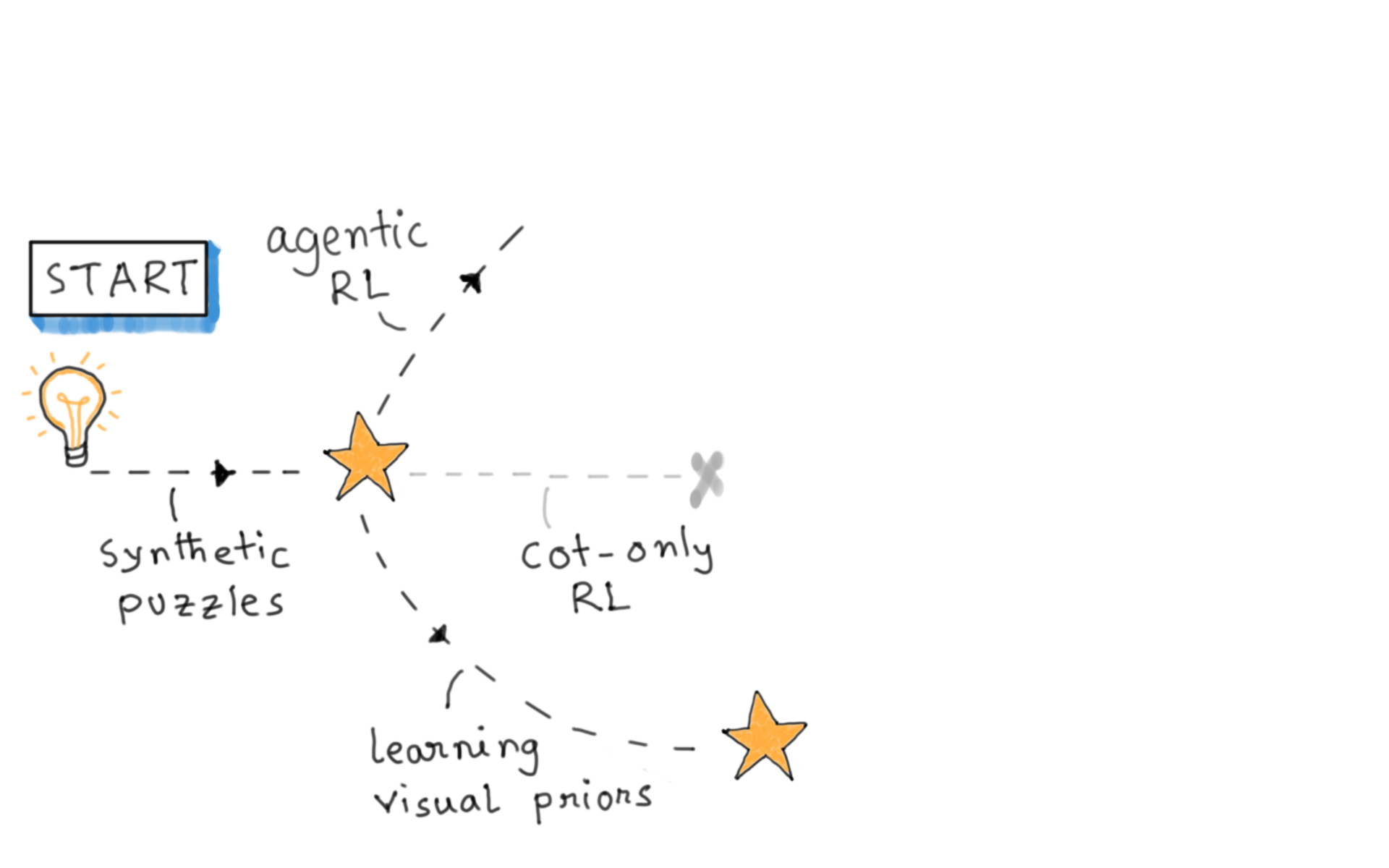
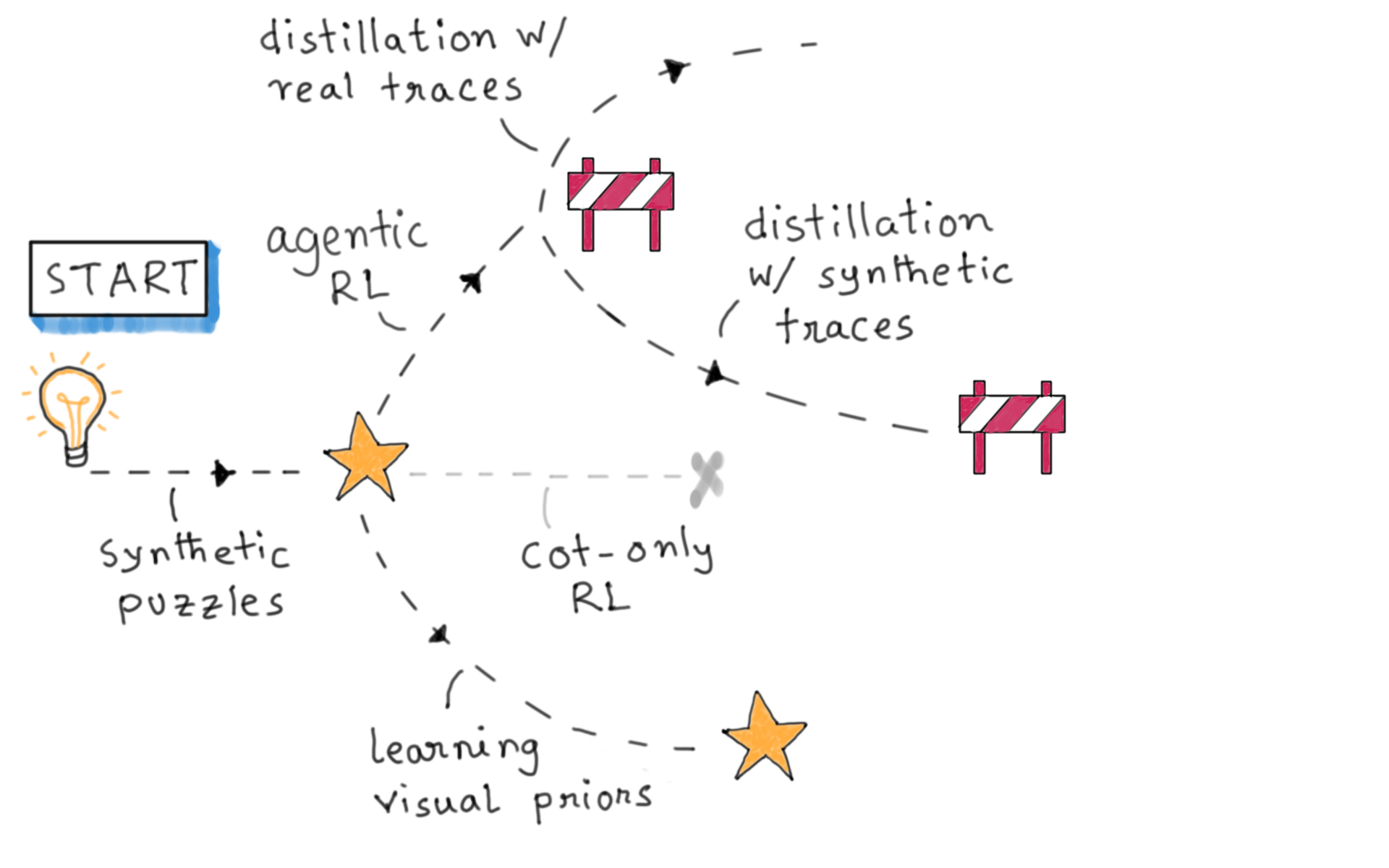
Our journey
Our journey

Our journey

Our journey
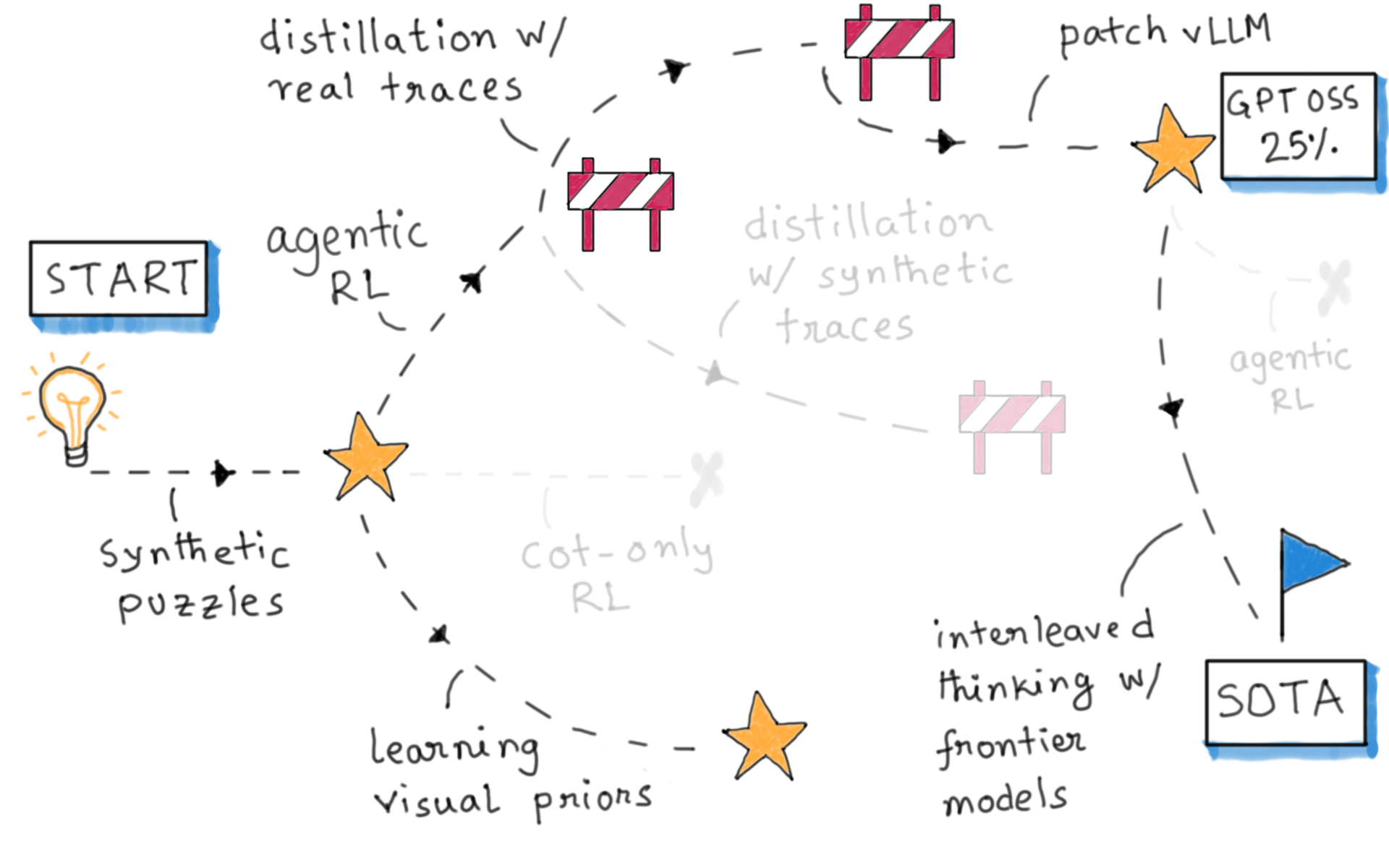
Let’s begin

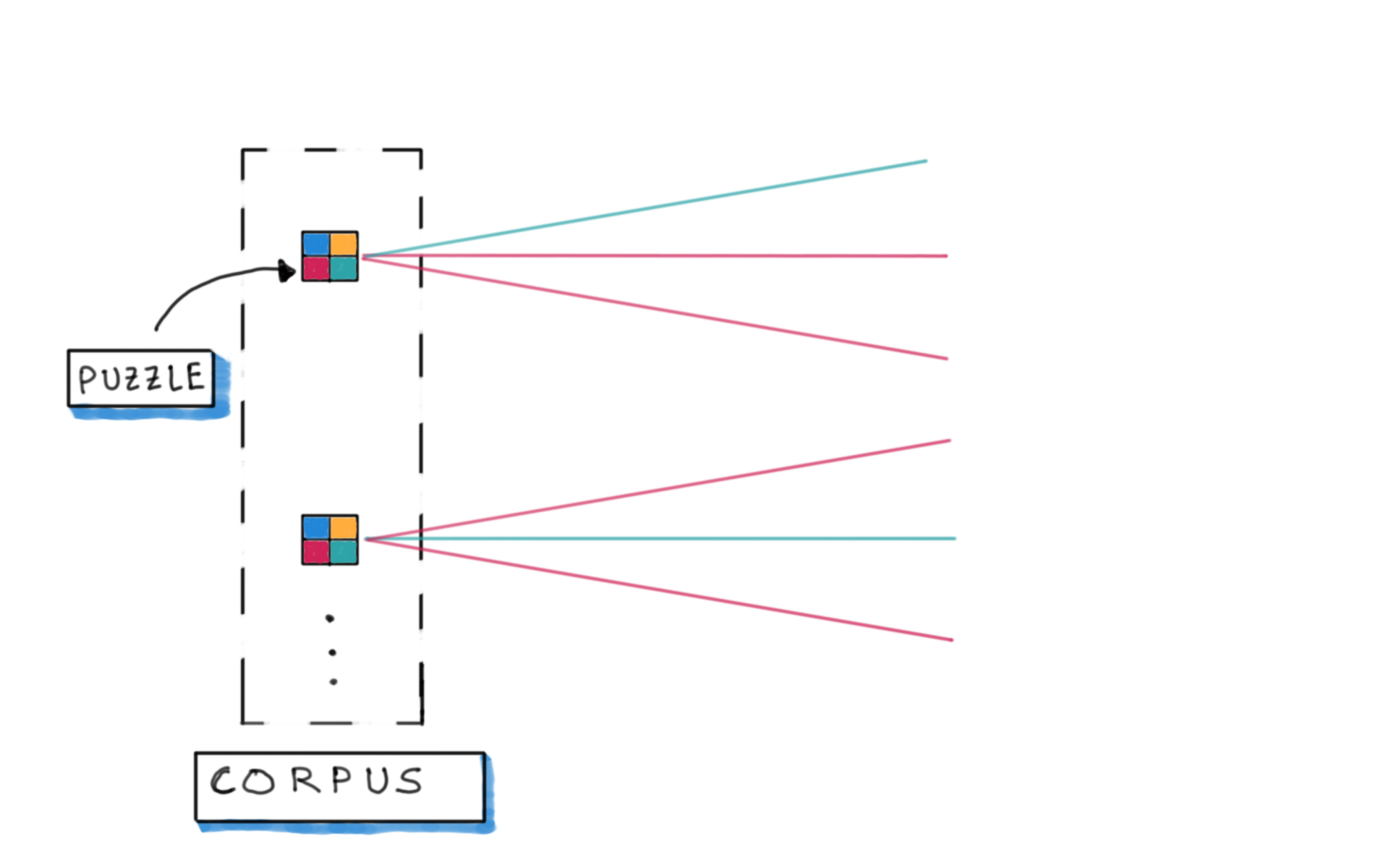
Training data
Solution trajectories
Solution trajectories

Solution trajectories
Solution trajectories
Rewards
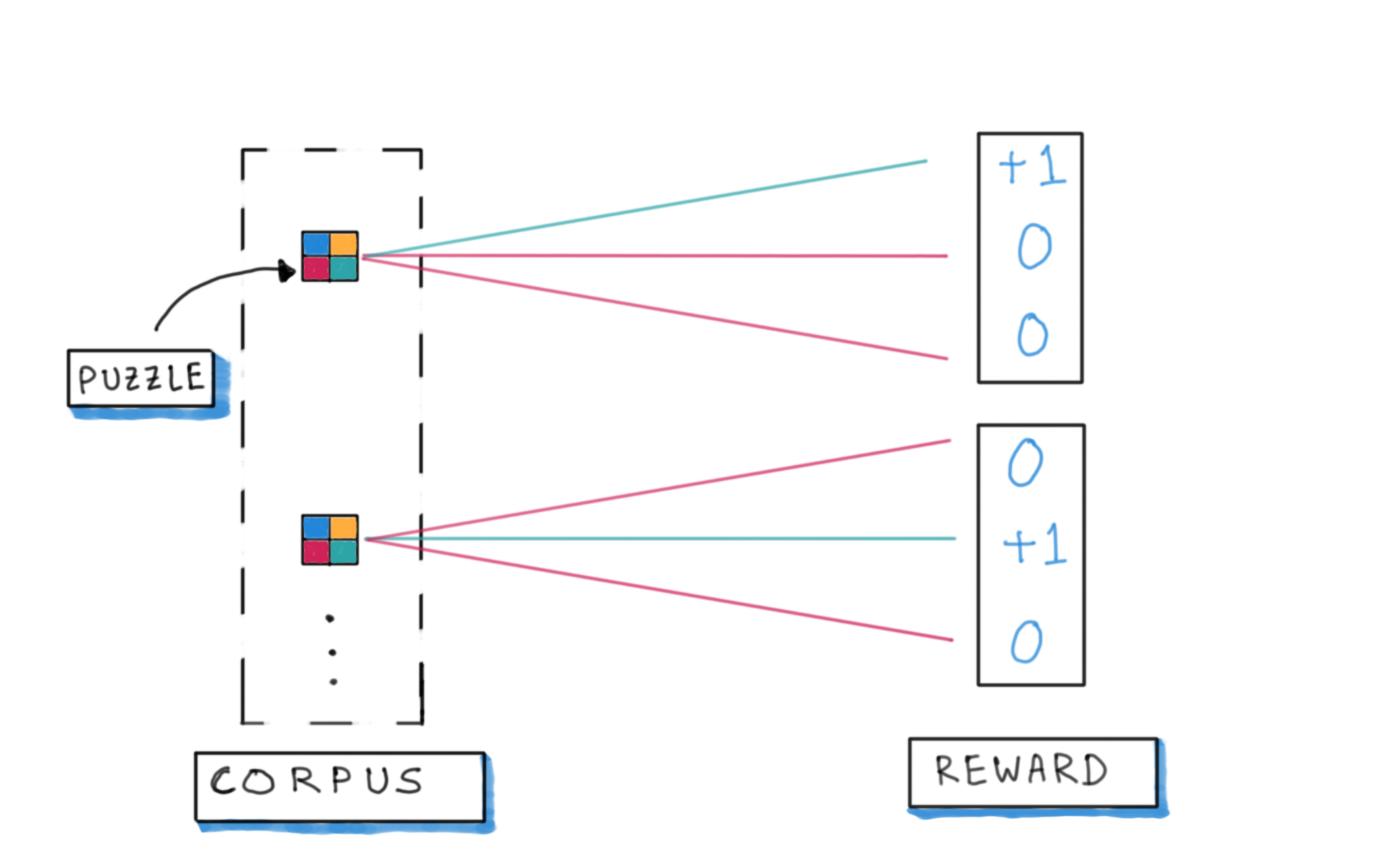
DeepSeek-R1 recipe: Reinforcement Learning
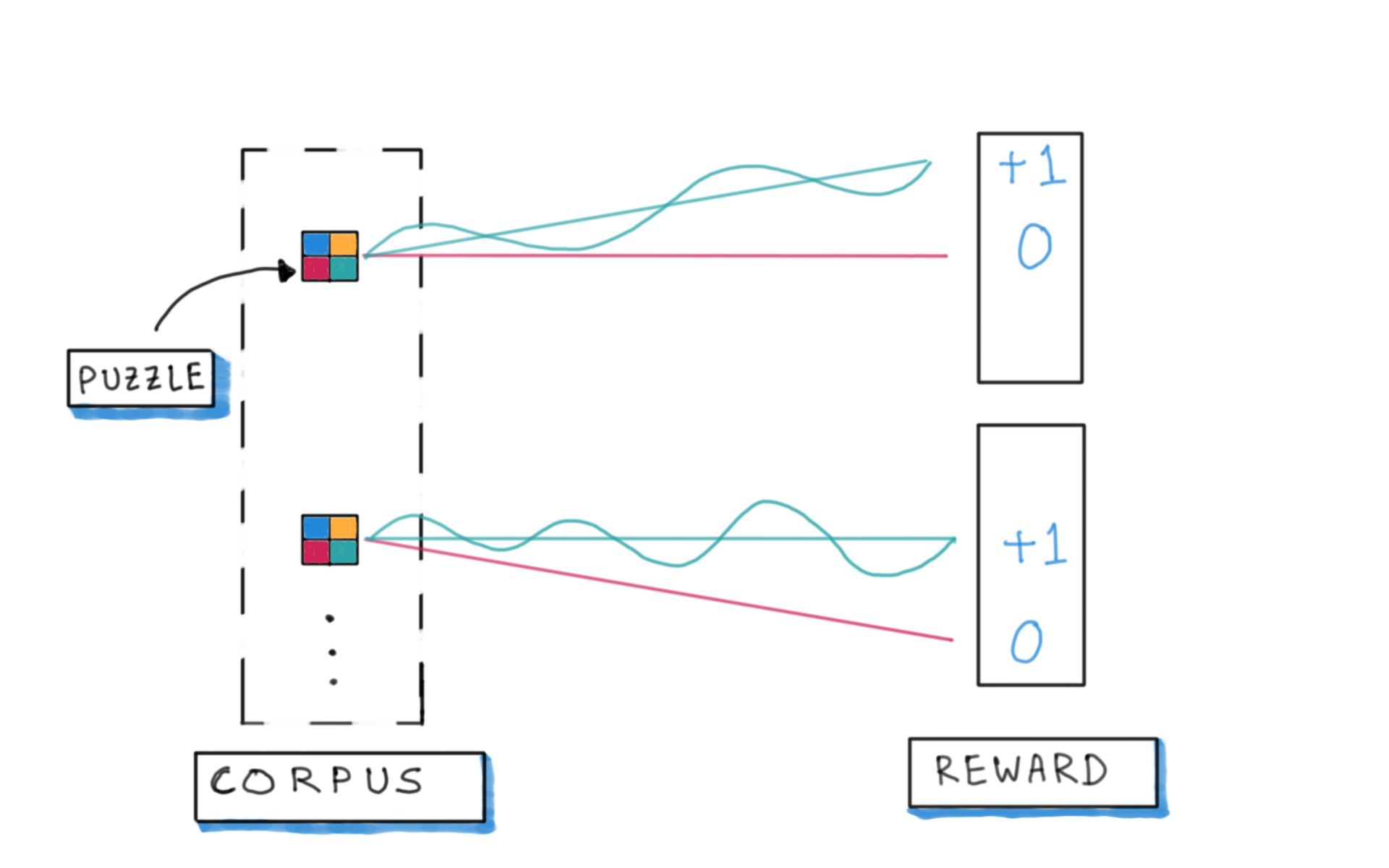
Problem: training data shortage
Problem: training data shortage
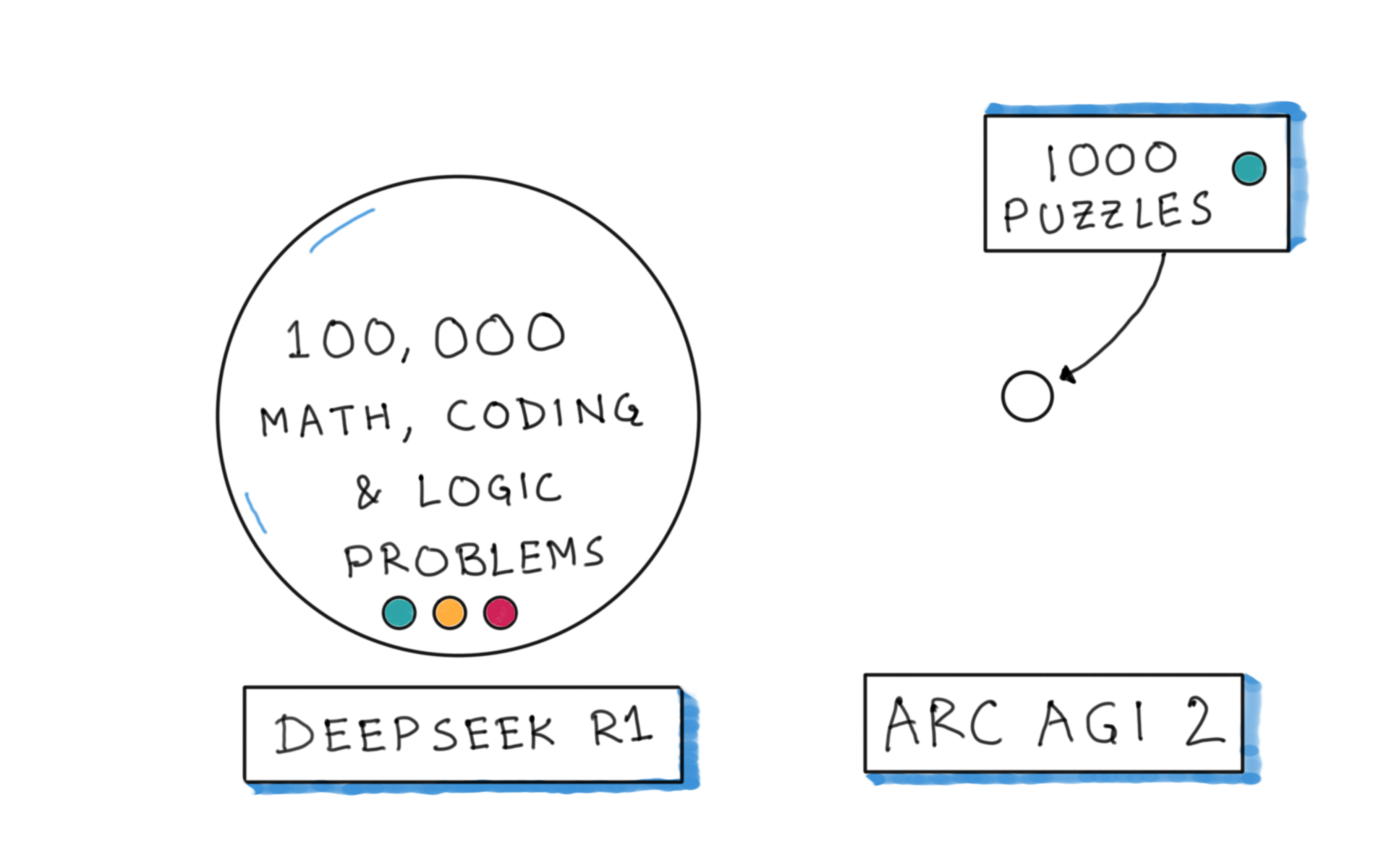
Solution: make synthetic puzzles
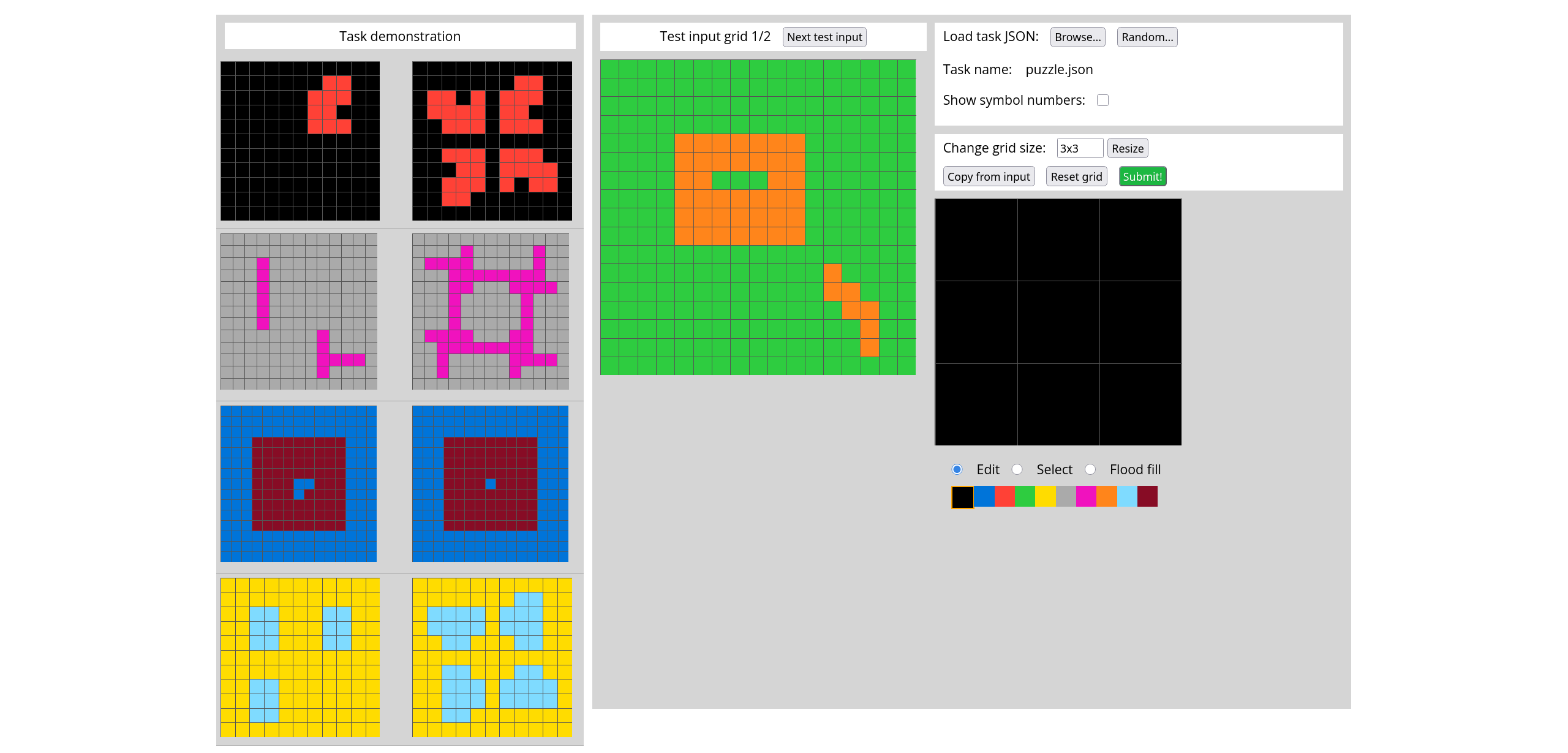
8000 synthetic puzzles, 671 concepts / priors
Complex, difficult puzzles like ARC AGI 2
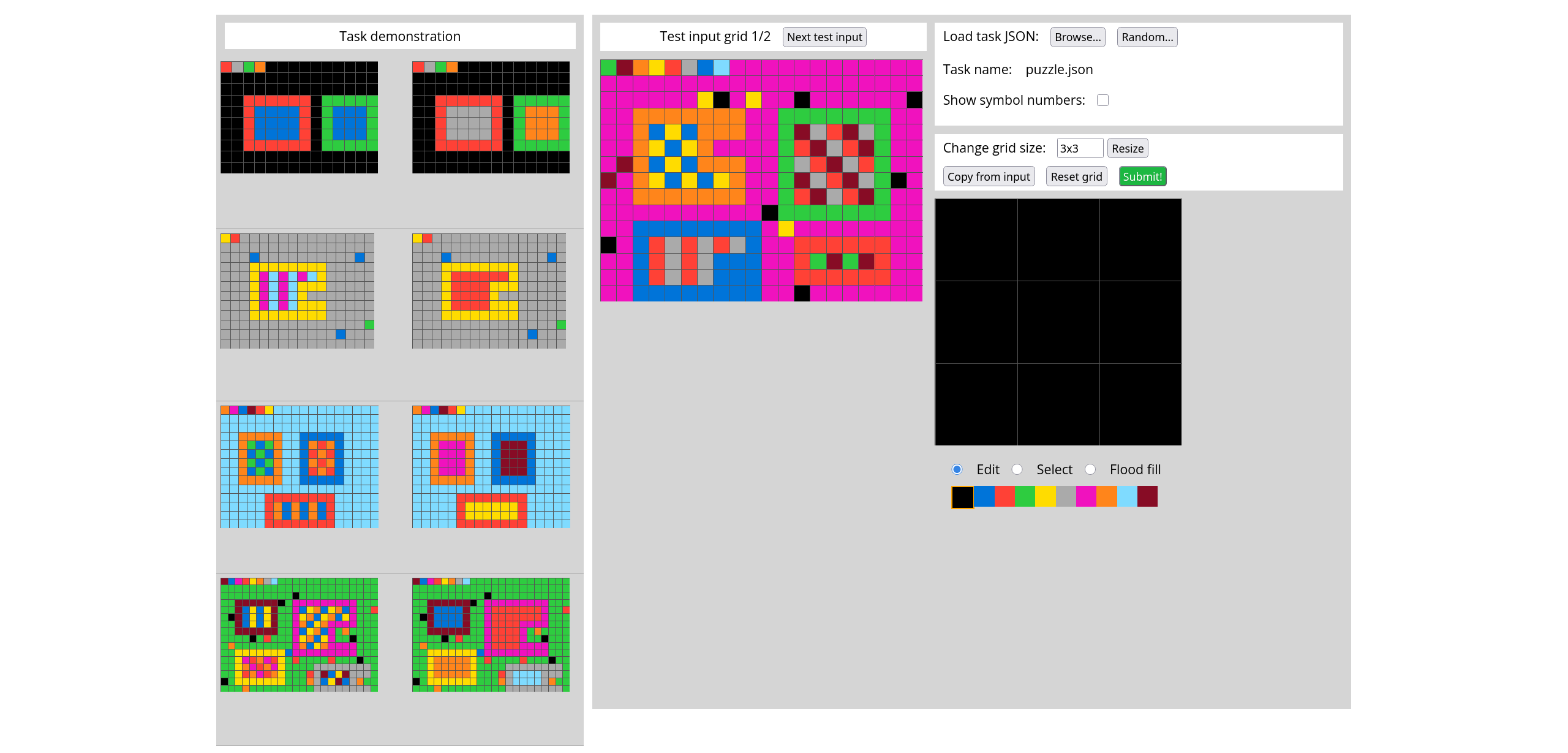
8000 synthetic puzzles, 671 concepts / priors
Complex, difficult puzzles like ARC AGI 2
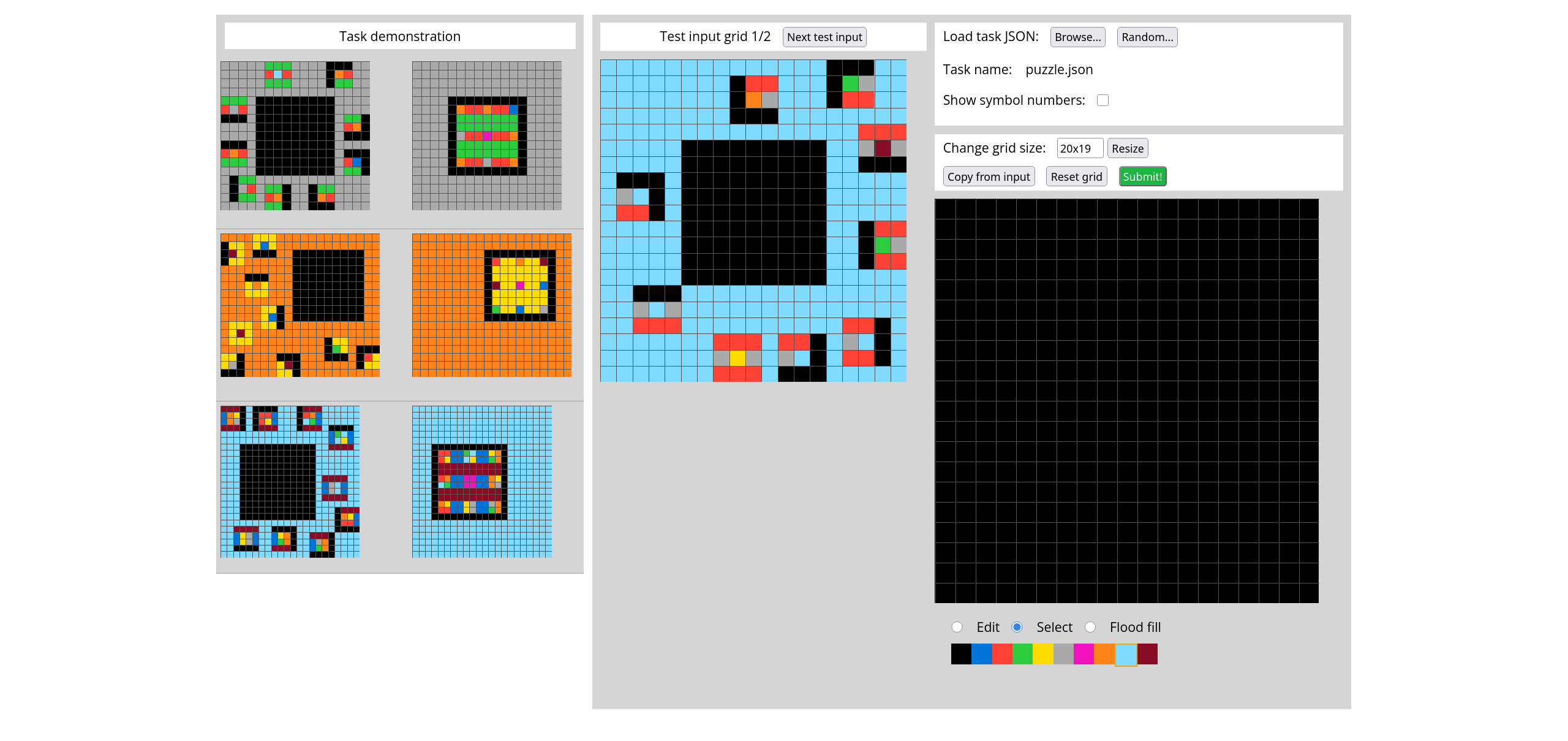
8000 synthetic puzzles, 671 concepts / priors
Complex, difficult puzzles like ARC AGI 2
Puzzle generation pipeline
Puzzle generation pipeline

Puzzle generation pipeline
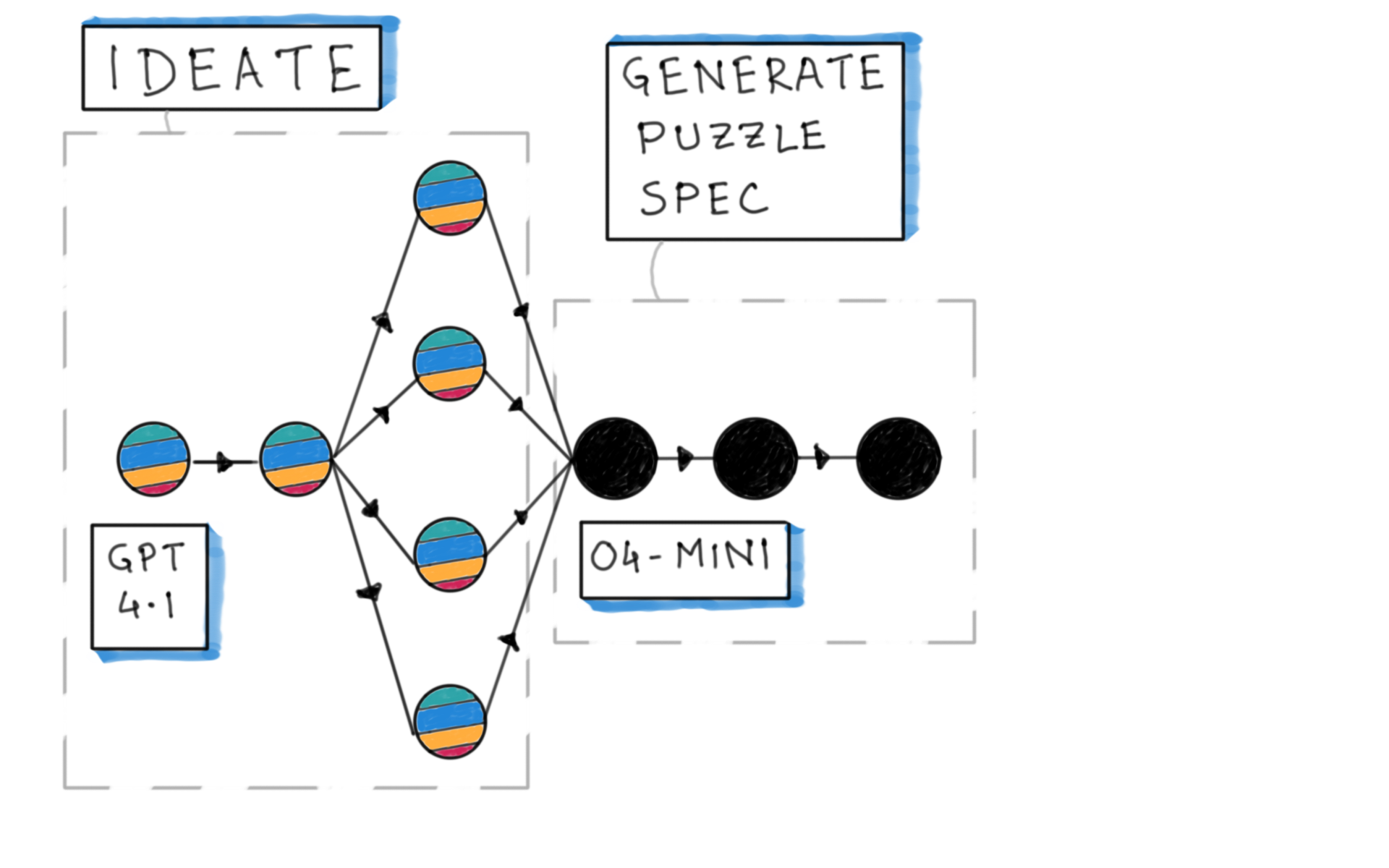
Puzzle generation pipeline
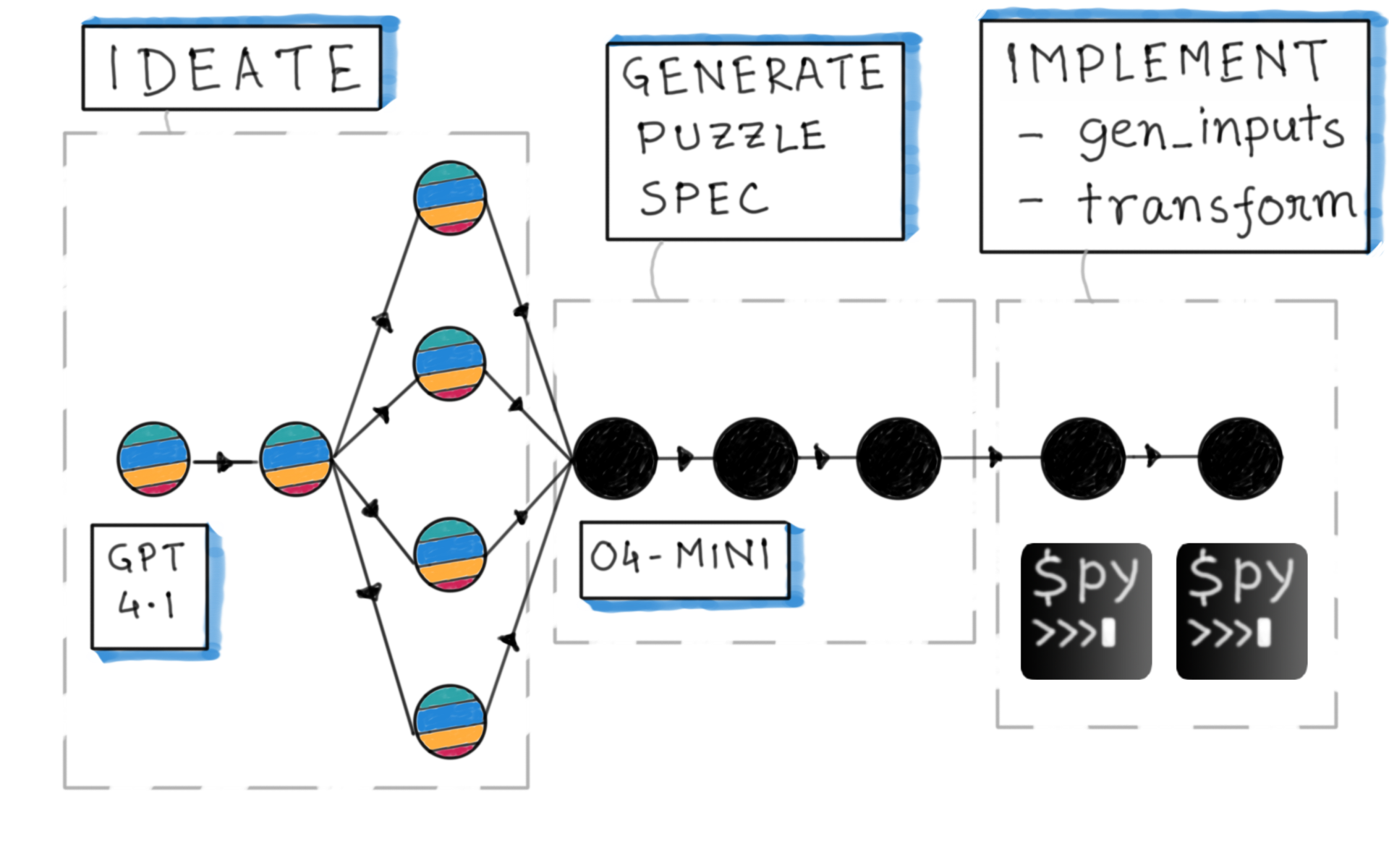
Lessons
Tool calling before o3 and o4-mini
Non-reasoning models e.g. gpt-4o

Tool calling before o3 and o4-mini
Reasoning models e.g. o1, Claude 4

Tool calling before o3 and o4-mini:
Reasoning models e.g. o1, Claude 4

Tool calling with o3 and o4-mini
Interleaved thinking

Interleaved thinking scales test-time compute
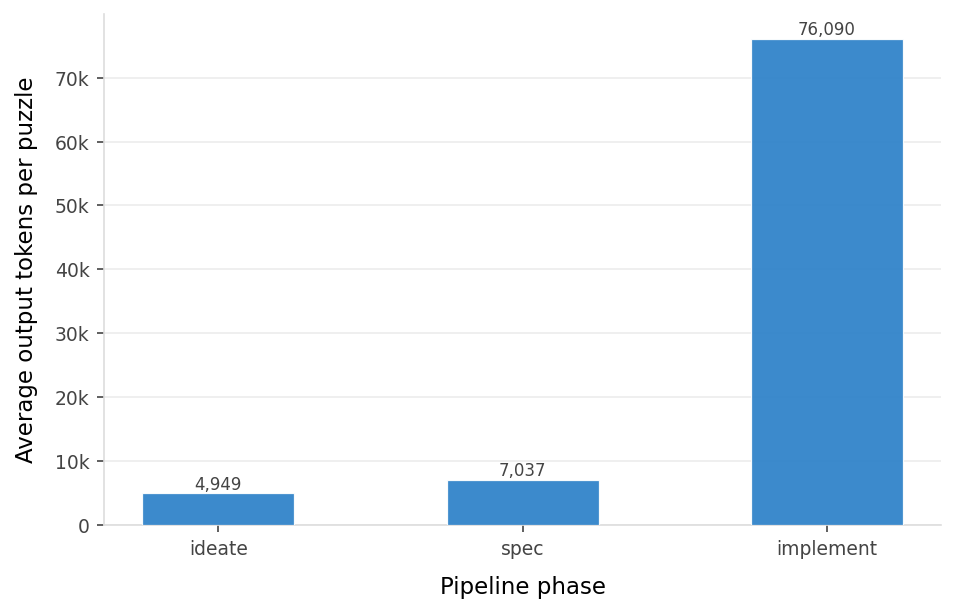
Instead of DeepSeek-R1 recipe…
Agentic RL
Our journey

Side quest: learning visual priors

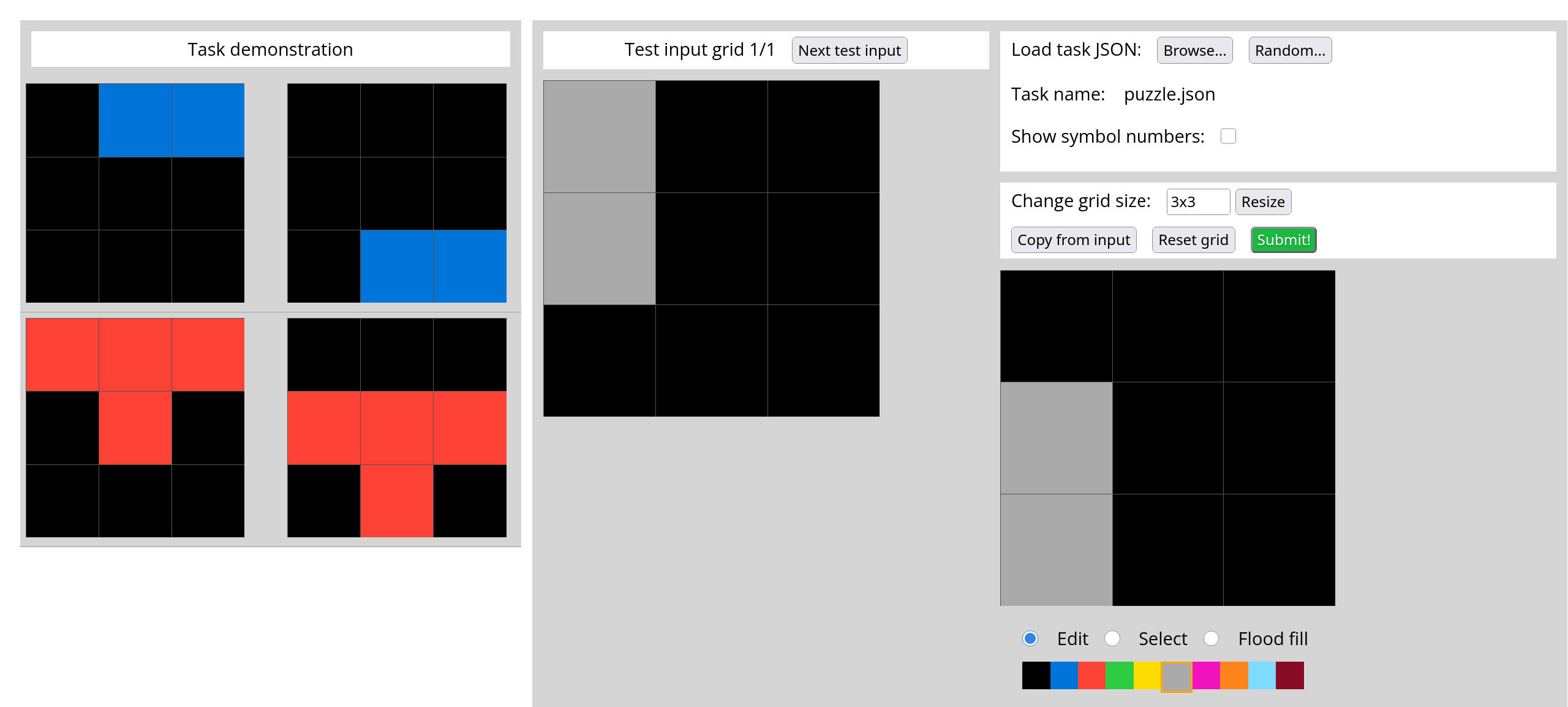
ARC AGI assumes core visual priors

- 9 chambers in 3 x 3 formation, separated by gray walls
- Each chamber contains a single shape
- 5 chambers have blue plus shapes
- 2 chambers have red T shapes
- 2 chambers have green Z shapes
Language models are efficient visual learners
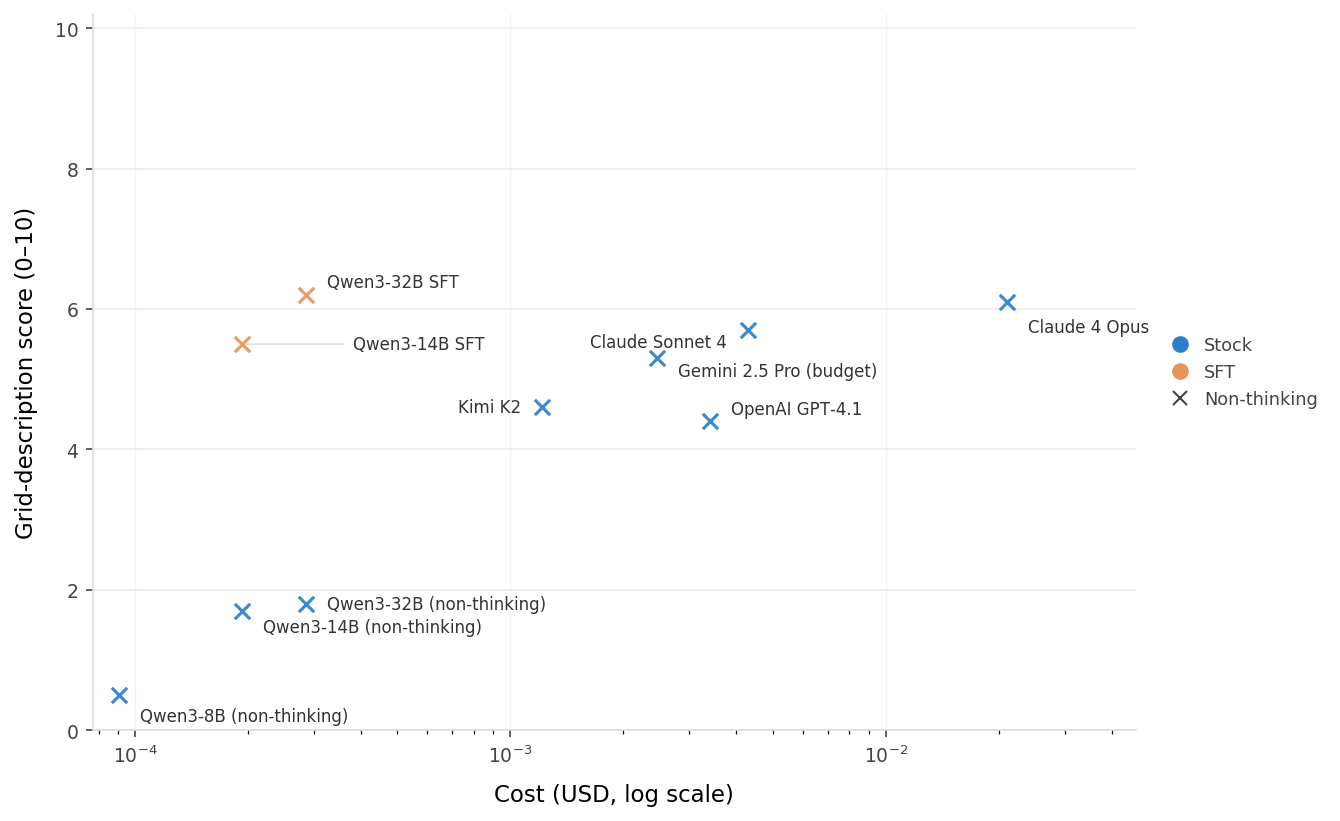
Language models are efficient visual learners
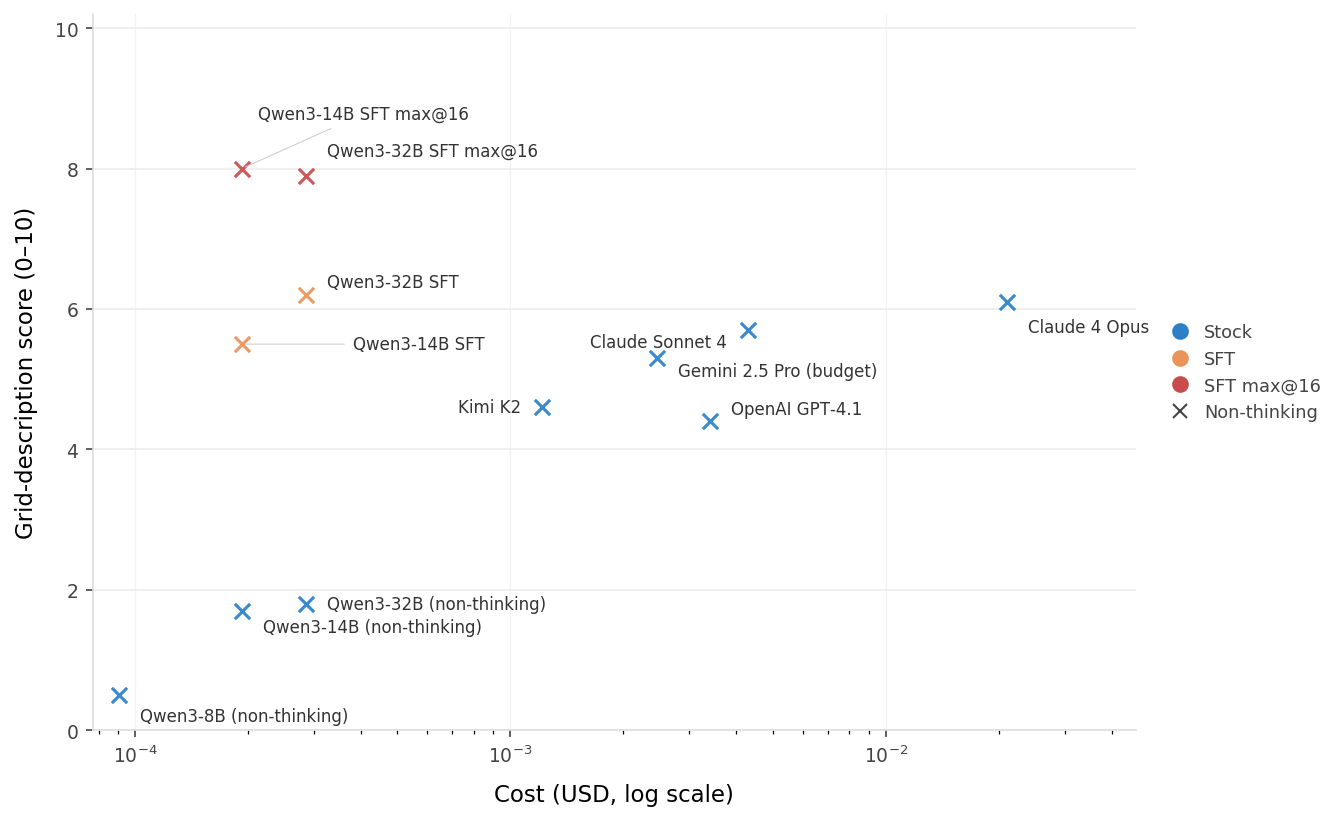
Qwen3-14B before and after fine-tuning

Before SFT (summary)
- Yellow pixels at (2,2), (2,3) …
- Navy cross at (5, 3), …
- Gray pixels at …
- Pink square at …
After SFT (summary)
- Yellow hollow square spanning row, col (3, 2) to (5, 4) with red central pixel
- Navy hollow square spanning … with green central pixel
- Green hollow square spanning … with yellow central pixel
- Pink hollow square spanning … with blue central pixel
- Surrounded by gray walls
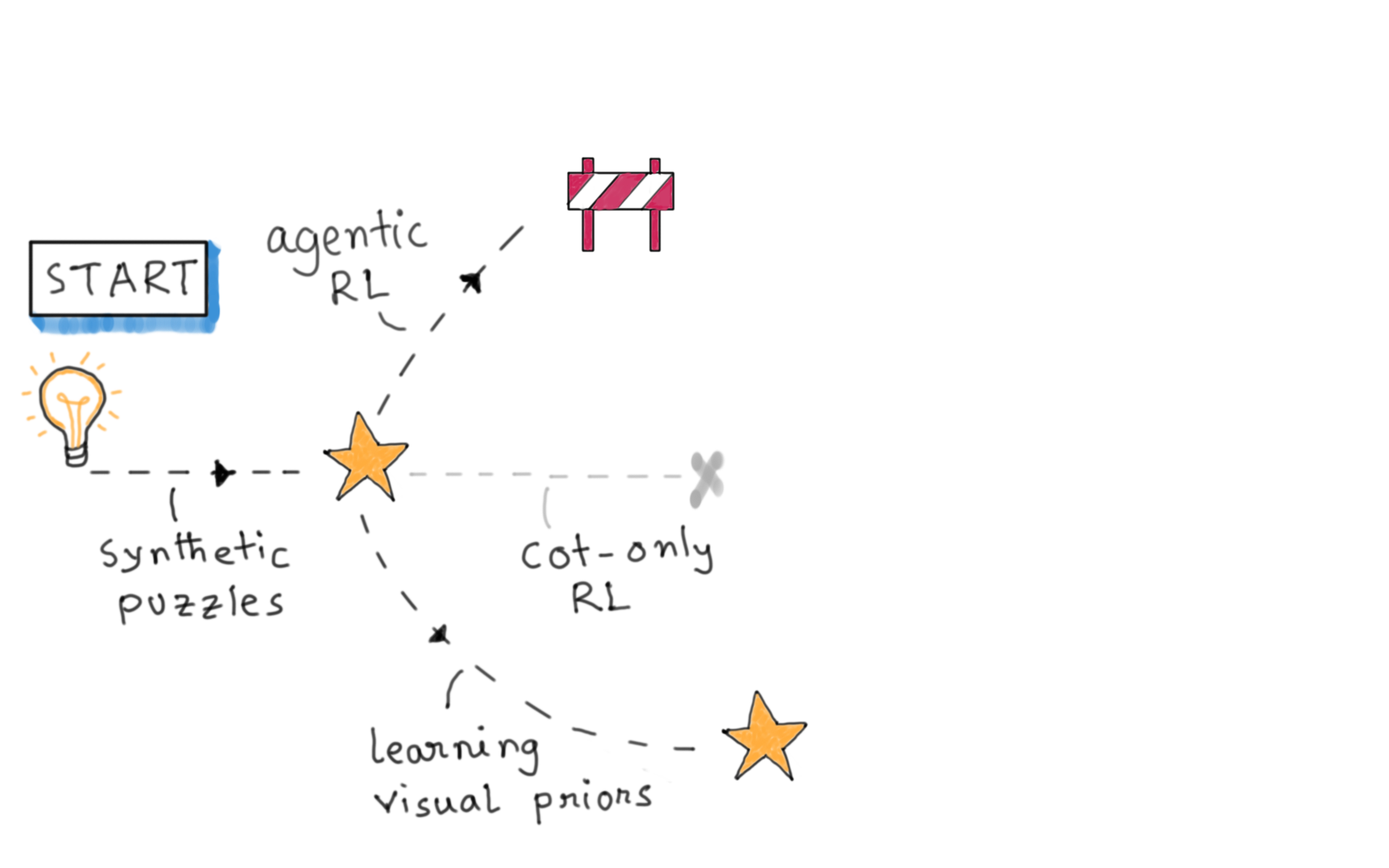
Our journey
Our journey
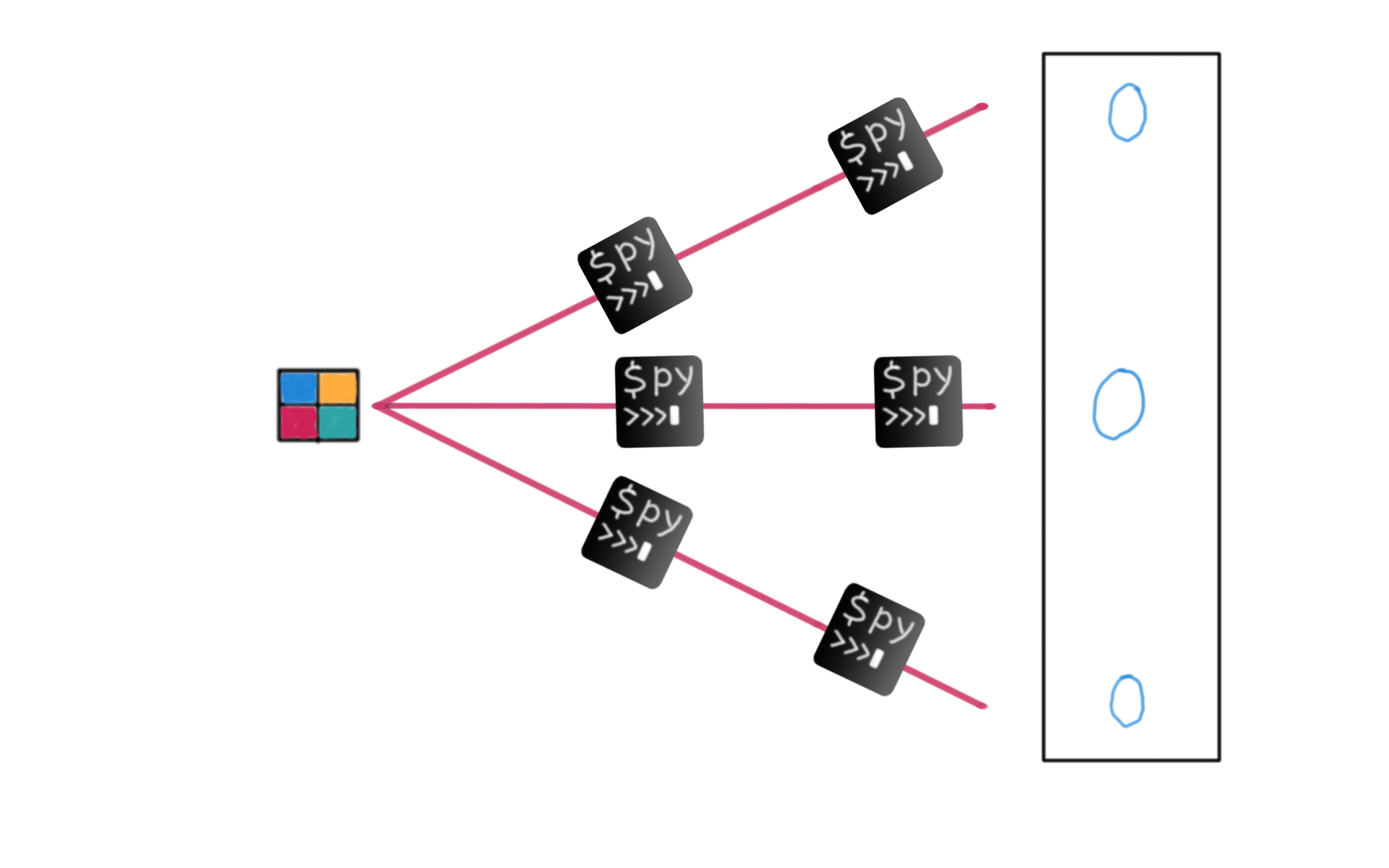
The plan
Reinforce the successes
The reality with Qwen3-14B
There’s nothing to reinforce
Solution: distillation from successful traces
Cold-start SFT
Solution: distillation from successful traces
Not all is well in the synthetic world
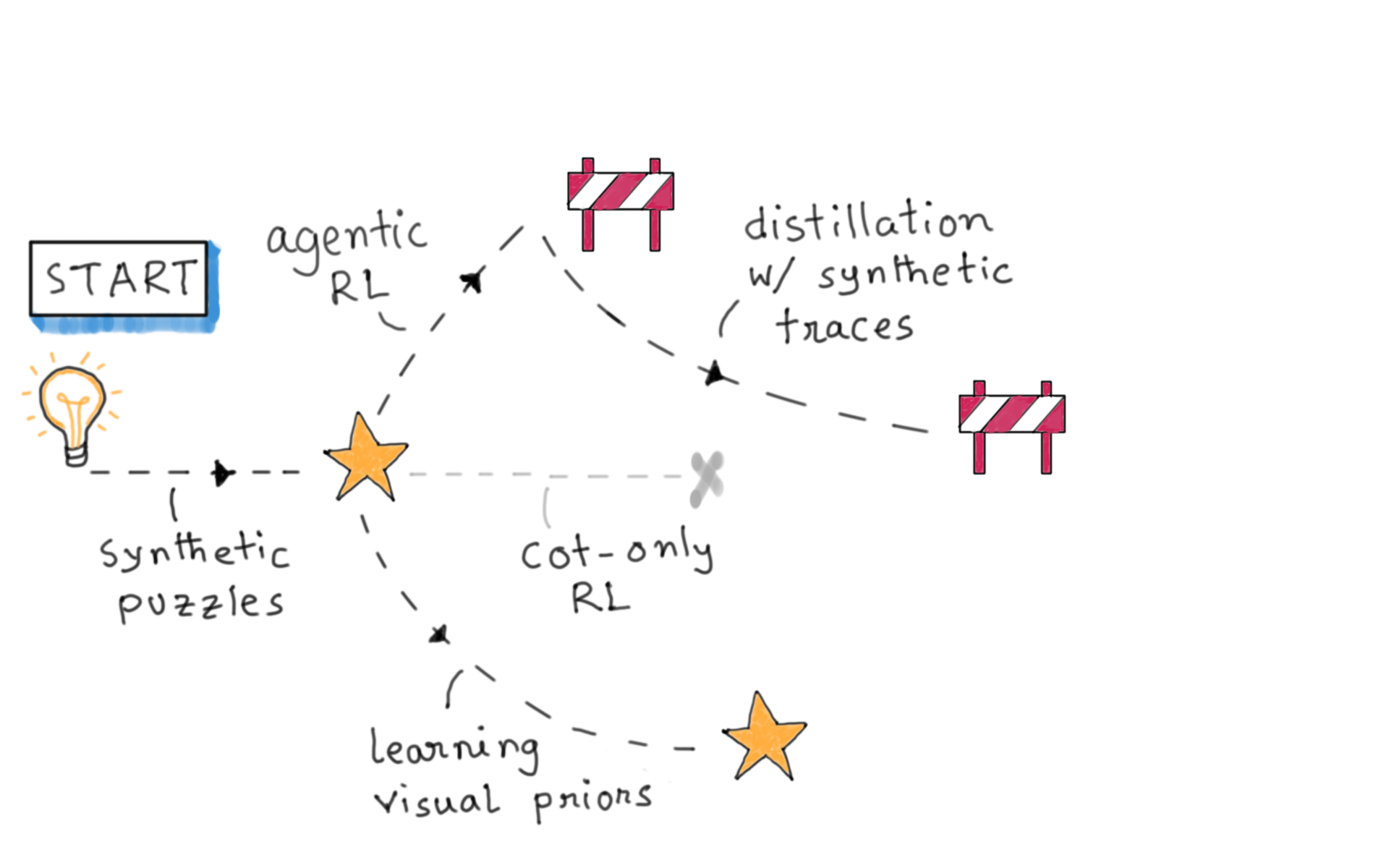
Solution: distillation from successful traces
This time, the real thing
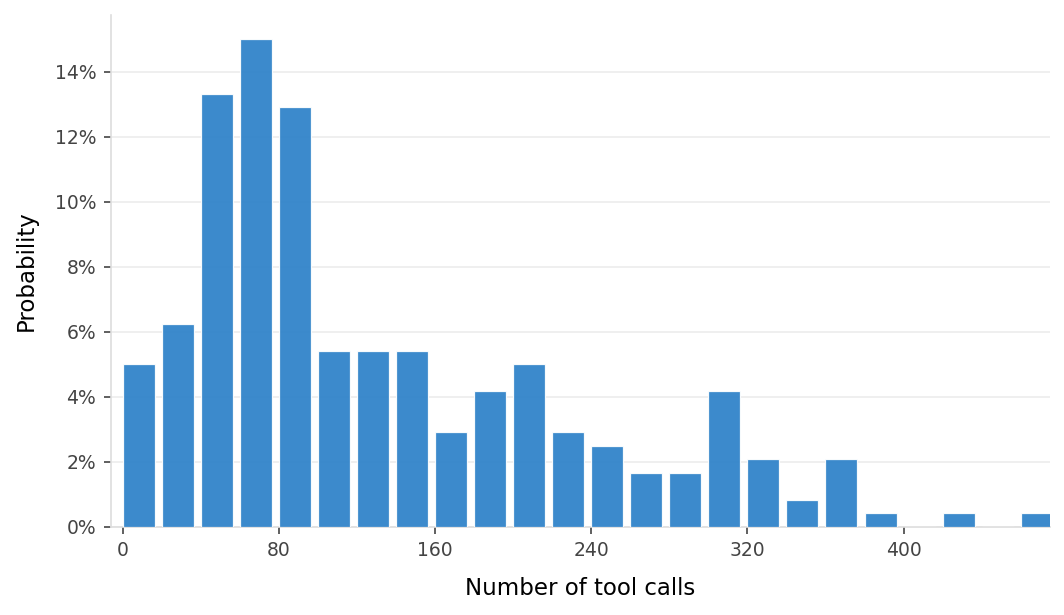
Inference providers we tried

Inference engines we tried
vLLM and SGLang on Lambda AI H100 and GH200 GPUs

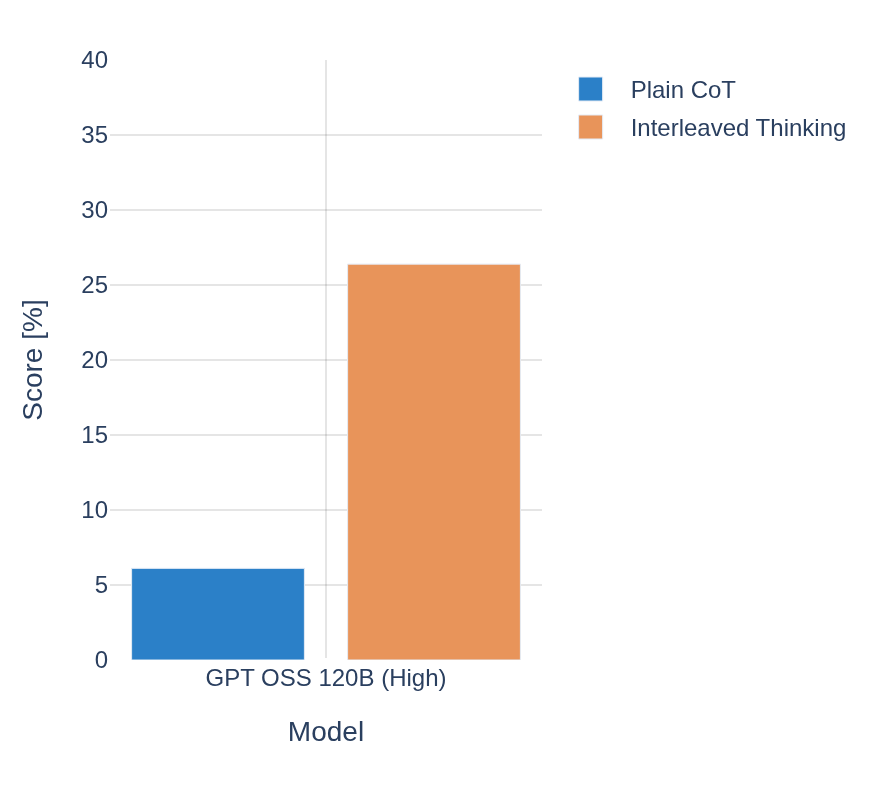
GPT OSS after fix
An interleaved thinking pro
GPT OSS after fix
Plain CoT vs interleaved thinking
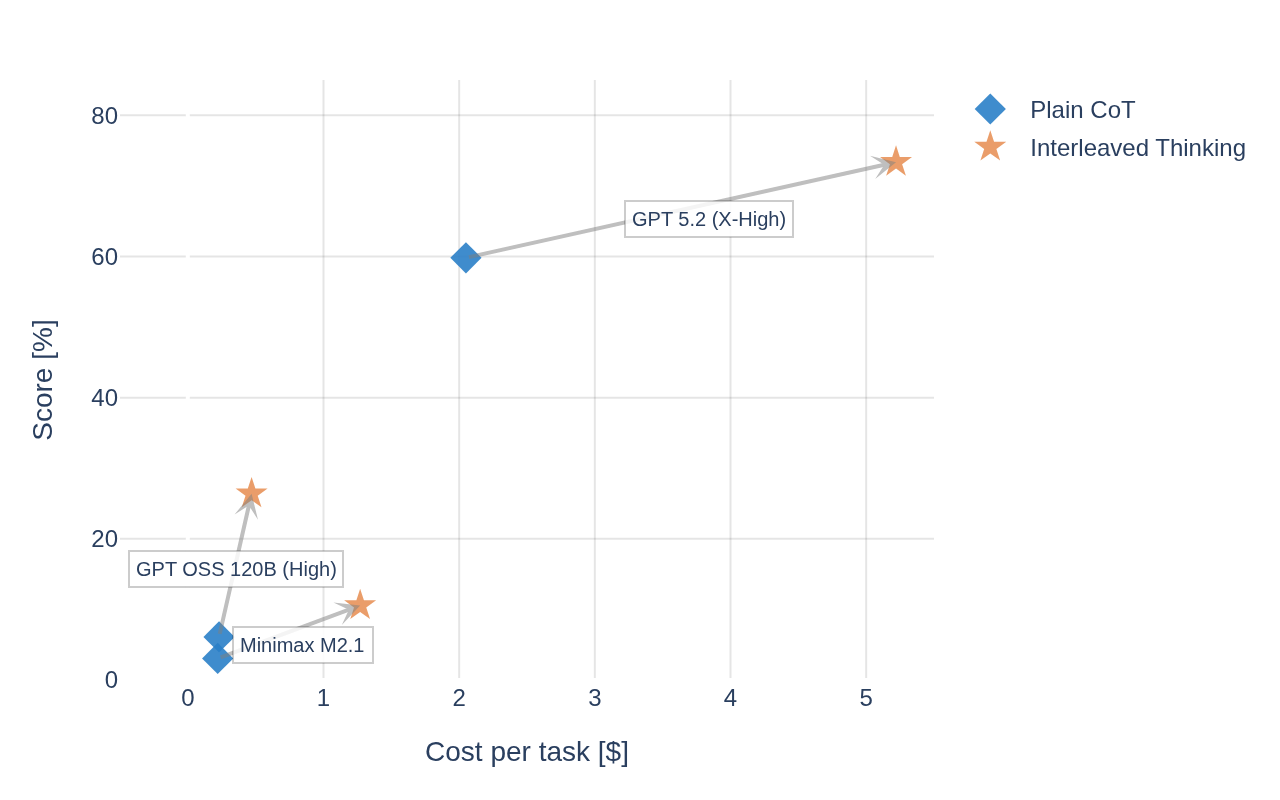
State of the art results
Our journey
Lessons learned along the way
Taking the birds eye view
- Tool use + reasoning ⟶ significant jump in LLM performance in reasoning tasks.
- Python (or similar tools) grounds the model - filter bad hypotheses early and replan.
- Labs underreported their flagship models’ performance on ARC because they evaluated without tool use.
- Small / open-weight models punch above their reputation
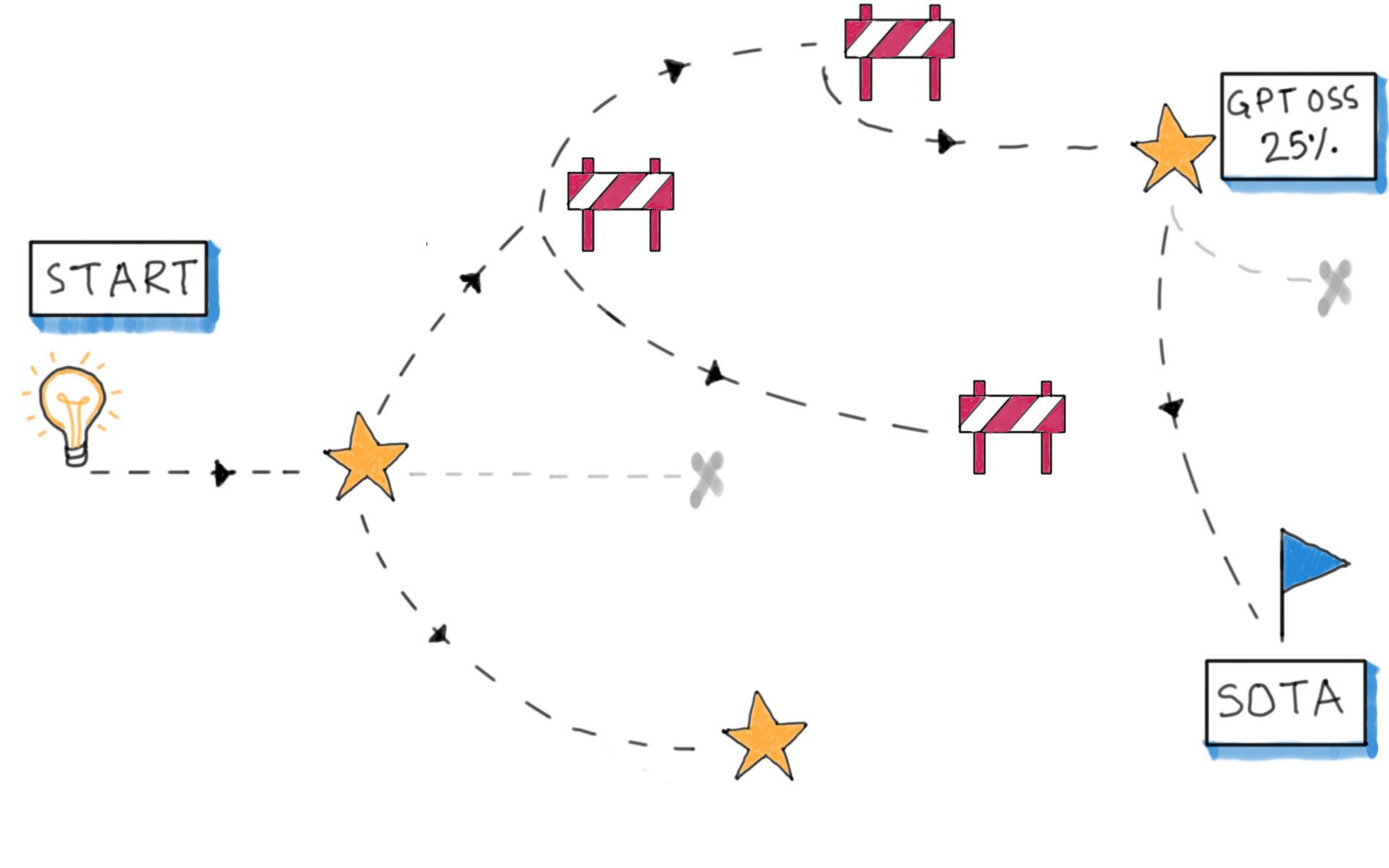
- We roughly 4×’d score on
gpt-oss-120bwith the right harness.
- We roughly 4×’d score on
- Synthetic data isn’t magic: Have to watch out for distribution shift.
- “Shortcut-y” traces skipped the messy reality of wrong hypotheses and recovery — undermines performance in inference time where replanning is necessary.
Simple sandbox physics solves the puzzle…
…on its own devices

What do you think? Do LLMs have fluid intelligence?
Good news for (us) physicists…
…still much to play with and discover (like parity symmetry)

Thank you for your attention!
Any Questions?